The classification of reviews into positive and negative classes is important because it lets us filter and sort based on the sentiment associated with a product or experience. This project explores two different representations of text reviews – unigrams (extracting single words) and bigrams (extracting pairs of words) and their impact on sentiment analysis.
Different classifiers, including support vector machines (SVM), random forests (RF), and logistic regression, were used to classify 2400 product reviews and their performance was evaluated on a testing set with 600 product reviews. After training the classifiers on both unigram and bigram representations of each review, the bigram representation results in a higher accuracy score, as seen in the graph below. Intuitively, this makes sense; bigrams are a more powerful representation as they can represent adverbs such as “not”, to be able to differentiate the sentiment “not good” from “good”.
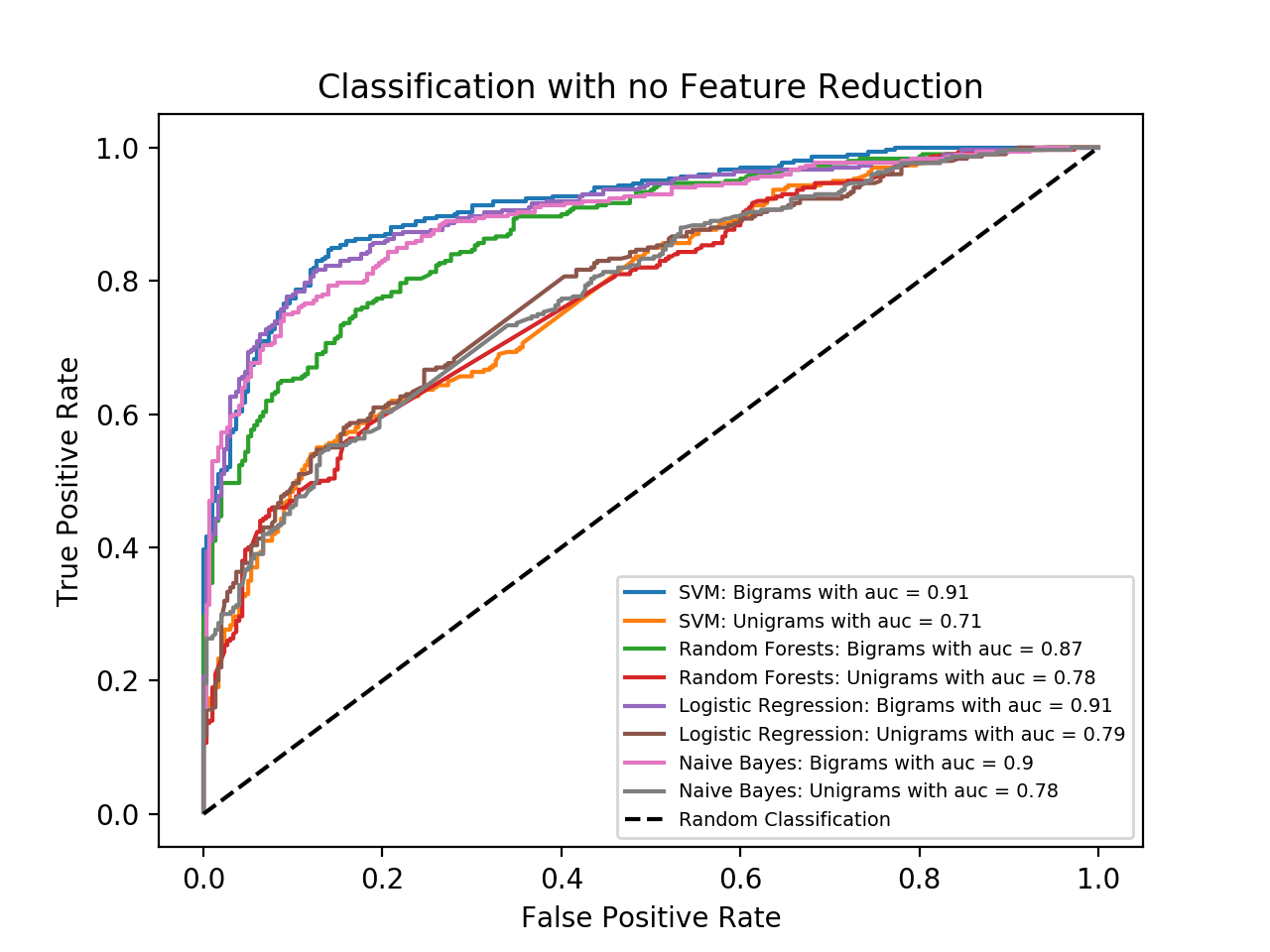
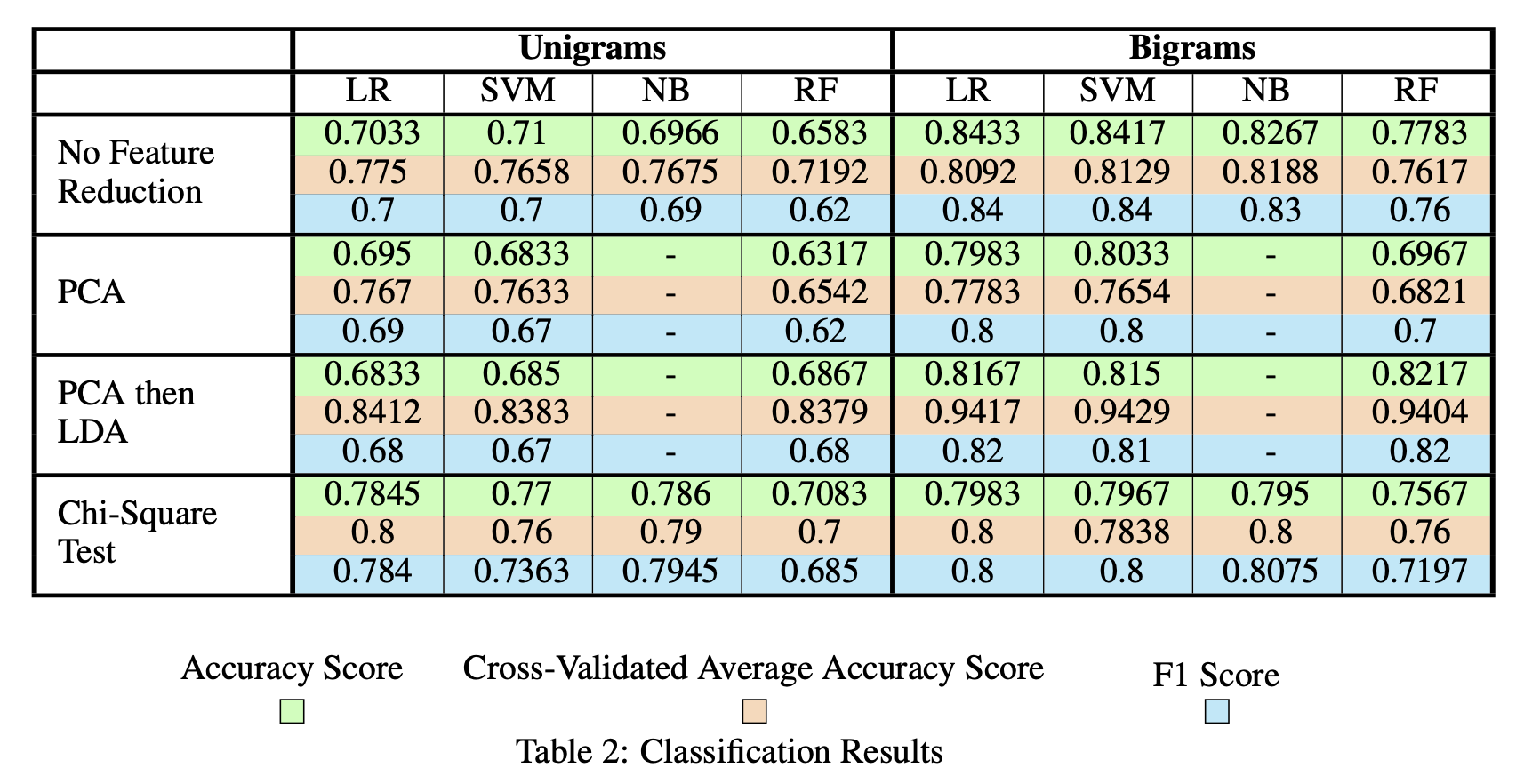
However, the bigrams representation of the reviews increased the complexity of the model. To address this, feature reduction techniques, such as principal component analysis (PCA), linear discriminant analysis (LDA), and the chi-square test, were employed to reduce the complexity of the bigram model to the unigram one. As seen in the table below, these feature reduction techniques reduce model complexity while preserving performance.
More details of this work are outlined in the paper attached.
